![[ KJ ] Week07](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdUydLY%2FbtsFGlwwsgG%2FFq0Hv4VVkkLgj6IKFgYWc1%2Fimg.png)
ꕥ
7주차 PintOS 프로젝트 중 Threads부터 시작했습니다~
ꕥ
- Project1 : Threads
멀티스레딩 : 하나의 프로세스 내에서 여러 스레드가 동시에 실행되는 기술
- 스레드를 어떻게 활용해서 효율적으로 사용할 건지?
1. Alarm Clock
- 문제점 : 현재 timer_sleep 함수는 목표 tick 시간 동안 while 루프에서 빠져나오지 못해, CPU가 다른 작업을 할 수 없게 된다.
// 프로그램의 실행을 대략적으로 ticks 타이머 틱 동안 정지
void timer_sleep(int64_t ticks_much)
{
int64_t ticks_now = timer_ticks();
ASSERT(intr_get_level() == INTR_ON);
// 양보를 얼마나 했는가
while (timer_elapsed(start) < ticks)
{
thread_yield();
}
}- 해결방안 : 목표 tick만큼 대기해야 하는 스레드를 대기 큐에 넣고, 목표 tick 시간이 지나면 대기 중인 스레드를 큐에서 꺼내 스레드의 상태를 준비 상태로 변경하도록 수정한다.
- 구현
thread.c
void thread_sleep(int64_t ticks_purpose)
{
struct thread *curr = thread_current();
// 현재 인터럽트 상태를 비활성화 후
// 이전 인터럽트 상태를 저장
enum intr_level old_level = intr_disable();
if (curr != idle_thread)
{
curr->ticks_sleep = ticks_purpose;
// sleep_list에 넣음
// curr->status = THREAD_BLOCKED;
list_push_back(&sleep_list, &curr->elem);
thread_block();
}
// 인터럽트 상태를 이전 상태로 복원
intr_set_level(old_level);
}
void thread_wake(int64_t ticks_wake)
{
// 현재 인터럽트 상태를 비활성화 후
// 이전 인터럽트 상태를 저장
enum intr_level old_level = intr_disable();
if (list_empty(&sleep_list))
{
return;
}
struct list_elem *list_ptr = list_begin(&sleep_list);
while (list_ptr != list_end(&sleep_list))
{
struct thread *t = list_entry(list_ptr, struct thread, elem);
if (ticks_wake >= t->ticks_sleep)
{
list_ptr = list_remove(list_ptr);
thread_unblock(t);
}
else
{
list_ptr = list_next(list_ptr);
}
}
intr_set_level(old_level); // 인터럽트 상태를 이전 상태로 복원
}
timer.c
// 프로그램의 실행을 대략적으로 ticks 타이머 틱 동안 정지
void timer_sleep(int64_t ticks_much)
{
int64_t ticks_now = timer_ticks();
ASSERT(intr_get_level() == INTR_ON);
if (timer_elapsed(ticks_now) < ticks)
{
thread_sleep(ticks_now + ticks_much);
}
}
static void timer_interrupt(struct intr_frame *args UNUSED)
{
ticks++;
thread_tick();
// 목표한 tick 도달 시 스레드 깨우기
thread_wake(ticks);
}
2. Priority Scheduling
- 문제점 : 현재는 어떤 스레드를 먼저 처리돼야야 할지 중요도가 높은 작업이 무엇인지 모르고 선입선출로 작업이 진행된다. 스레드에게 우선순위가 없으면 작업 순서를 설정할 수 없다.
- 해결방안 : 스레드에게 우선순위를 부여해 중요도 순으로 내림차순 정렬하여 스레드를 관리한다. 그러나 높은 우선순위가 대기 중이면 우선순위의 역전이 발생할 수 있다. 이것을 해결하기 위해 현재 락 해제를 대기하고 있는 스레드들 중, 우선순위가 가장 높은 것을 락 홀더에게 기부하여 높은 우선순위를 가진 스레드가 작업을 먼저 수행할 수 있도록 한다.
- 구현
thread.c
void thread_unblock(struct thread *t)
{
enum intr_level old_level;
ASSERT(is_thread(t));
old_level = intr_disable();
ASSERT(t->status == THREAD_BLOCKED);
list_insert_ordered(&ready_list, &t->elem, cmp_big_priority, NULL);
t->status = THREAD_READY;
intr_set_level(old_level);
}
void thread_yield(void)
{
struct thread *curr = thread_current();
enum intr_level old_level;
ASSERT(!intr_context());
old_level = intr_disable();
// 현재 스레드가 노는 스레드가 아니라면
if (curr != idle_thread)
{
// 우선순위대로 ready_list에 삽입
list_insert_ordered(&ready_list, &curr->elem, cmp_big_priority, NULL);
// 준비된 스레드 목록에 삽입
// list_push_back(&ready_list, &curr->elem);
}
// RUNNING 스레드를 READY로 대기
do_schedule(THREAD_READY);
intr_set_level(old_level);
}
synch.c
void lock_acquire (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (!lock_held_by_current_thread (lock));
struct thread *cur = thread_current();
if(!thread_mlfqs)
{
if (lock->holder) {
// Todo 1
cur->wait_on_lock = lock;
// Todo 2
list_insert_ordered(&(lock->holder->donation_list), &(cur->donation_elem), cmp_lock_priority, NULL);
// Todo 3
donate_priority();
}
}
sema_down (&lock->semaphore);
lock->holder = cur;
}
bool cmp_lock_priority(struct list_elem *cur, struct list_elem *cmp, void *aux UNUSED) {
return list_entry(cur, struct thread, donation_elem)->priority > \
list_entry(cmp, struct thread, donation_elem)->priority \
? true : false;
}
void donate_priority (void) {
struct thread *cur = thread_current ();
while (cur->wait_on_lock != NULL){
struct thread *holder = cur->wait_on_lock->holder;
if (cur->priority > holder->priority)
holder->priority = cur->priority;
cur = holder;
}
}
void lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock));
if(!thread_mlfqs)
{
struct list_elem *e = list_begin(&(lock->holder->donation_list));
int max_priority = lock->holder->origin_priority;
while (e != list_end(&(lock->holder->donation_list))) {
struct thread *t = list_entry(e, struct thread, donation_elem);
if (t->wait_on_lock == lock) {
t->wait_on_lock = NULL;
e = list_remove(e);
} else {
if (t->priority > max_priority)
max_priority = t->priority;
e = list_next(e);
}
}
lock->holder->priority = max_priority;
}
lock->holder = NULL;
sema_up (&lock->semaphore);
}
3. Advanced Scheduler
- 문제점 : 프로그램에서 생성되는 스레드는 여러 작업을 수행하는데, 입출력 I/O 작업과 같이 빠른 응답 속도를 가져야 하는 스레드의 작업은 다른 작업보다 우선순위를 높게 갖기 때문에, 이미 입출력 I/O 작업이 많은 스레드가 프로그램에서 동작하는 중이라면 그 외 CPU를 많이 사용해야 하는 다른 스레드의 작업은 수행하지 못할 수 있다.
- 해결방안 : 모든 스레드에 대한 우선순위를 nice 정수 값, recent cpu 실수 값, load average 실수 값을 통해 우선순위 값을 일정 시간마다 갱신해 주고 작업을 효율적으로 진행한다. 또한 실수 값을 연산하기 위해 pintos에서는 고정소수점 사용해서 실수 값을 나타낸다.
- 구현
thread.c
void
increase_recent_cpu(void)
{
struct thread *cur_thread = thread_current();
int recent = cur_thread->recent_cpu;
if(cur_thread != idle_thread)
cur_thread->recent_cpu = add_mixed(recent, 1);
}
void
recalculate_priority(void)
{
struct thread *cur_thread = thread_current();
struct list_elem *temp_elem;
if(cur_thread != idle_thread)
cur_thread->priority = priority_cal(cur_thread->recent_cpu, cur_thread->nice) /*(int)(PRI_MAX - (cur_thread->recent_cpu / 4) - (cur_thread->nice * 2))*/;
for(temp_elem = list_begin(&ready_list); temp_elem != list_end(&ready_list); temp_elem = list_next(temp_elem))
{
struct thread *temp_thread = list_entry(temp_elem, struct thread, elem);
temp_thread->priority = priority_cal(temp_thread->recent_cpu, temp_thread->nice) /*(int)(PRI_MAX - (temp_thread->recent_cpu / 4) - (temp_thread->nice * 2))*/;
}
}
int priority_cal(int recent, int nice)
{
int fp_recent_cpu = div_mixed(recent, 4);
int fp_pri_max = int_to_fp(PRI_MAX);
int sub_recent_from_max = sub_fp(fp_pri_max, fp_recent_cpu);
return fp_to_int_round(sub_mixed(sub_recent_from_max, (nice * 2)));
}
void recalculate_recent_cpu(void)
{
struct thread *cur_thread = thread_current();
struct list_elem *temp_elem;
int nice = cur_thread->nice;
int recent_cpu = cur_thread->recent_cpu;
if(cur_thread != idle_thread)
cur_thread->recent_cpu = recent_cpu_cal(recent_cpu, load_avg, nice);
for(temp_elem = list_begin(&ready_list); temp_elem != list_end(&ready_list); temp_elem = list_next(temp_elem))
{
struct thread *temp_thread = list_entry(temp_elem, struct thread, elem);
int nice = temp_thread->nice;
int recent_cpu = temp_thread->recent_cpu;
temp_thread->recent_cpu = recent_cpu_cal(recent_cpu, load_avg, nice);
}
}
int recent_cpu_cal(int recent_cpu, int load_avg, int nice)
{
int decay = div_fp(load_avg * 2, add_mixed((load_avg * 2), 1));
return add_mixed(mult_fp(decay, recent_cpu), nice);
}
void recalculate_load_avg(void)
{
struct thread *cur_thread = thread_current();
int size = list_size(&ready_list);
int ready_threads_count = cur_thread == idle_thread ? size : size + 1;
load_avg = load_avg_cal(load_avg, ready_threads_count);
}
int load_avg_cal(int load, int ready_threads)
{
int fp_59 = int_to_fp(59);
int fp_1 = int_to_fp(1);
return add_fp(mult_fp(div_mixed(fp_59, 60), load),
mult_mixed(div_mixed(fp_1, 60), ready_threads));
}
timer.c
static void
timer_interrupt (struct intr_frame *args UNUSED) {
struct thread *cur_thread = thread_current();
ticks++;
thread_tick ();
thread_awake(ticks);
// increase recent_cpu value of current thread
if(thread_mlfqs)
{
increase_recent_cpu();
if(ticks % TIMER_FREQ == 0)
{
// recalculate load_avg value
recalculate_load_avg();
// recalculate recent_cpu value
recalculate_recent_cpu();
}
if(ticks % 4 == 0)
{
// recalculate all threads priority
recalculate_priority();
}
}
}- 테스트 결과
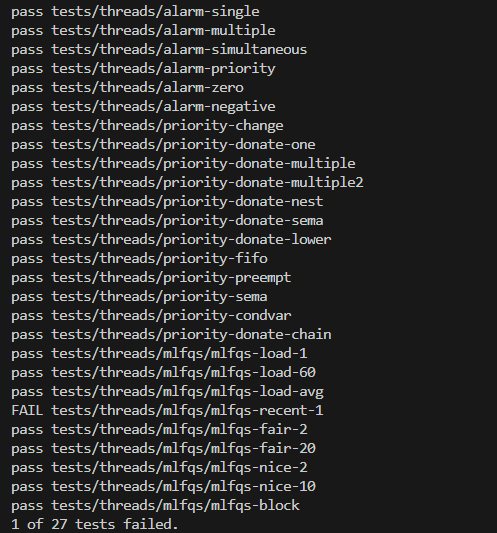
- 어려웠던 점
< 추성결 >
- Alarm Clock 구현 시 스레드 동작 과정에 대한 전체적인 흐름을 이해하기 어려웠고, 현재 time_interrupt에서 매 tick 당 sleep_list의 요소를 탐색하여 sleep tick을 확인하는 과정에서 매 tick 당 O(N^2)의 시간이 소모되는 매우 비효율적인 작업을 수정하지 못한 것이 아쉬웠다.
- Priority Schedule에서는 Lock의 Acquire와 Release과정의 전체적인 그림이 머릿속으로 그려지지 않아 lock_release함수에서의 donation 원복 작업이 어려웠다.
- Advanced Schedule에서는 sema_waiters와 sleep_list의 thread들의 recent_cpu의 값을 갱신해줘야하는 이유를 알지 못했다.
- 디버깅 시, pintos내에서는 tick으로 프로그램이 실행되기 때문에 printf()를 찍었을 때 테스트를 패스하는 경우가 있어 디버깅 작업에 어려움을 느꼈다.
< 김수빈 >
- 스레드의 상태 전환 흐름이 이해하기 어려워 Alarm Clock 기능을 구현하는데 있어 어려웠다.
- lock에 대한 권한 할당과 해제가 어떤 식의 흐름으로 이루어져 있는지 어려웠다.
'Krafton Jungle' 카테고리의 다른 글
| [ KJ ] Week08 (0) | 2024.03.21 |
|---|---|
| [ KJ ] Week06 (0) | 2024.02.29 |
| [ KJ ] Week05 (1) | 2024.02.23 |
| [ KJ ] Week04 (0) | 2024.02.07 |
| [ KJ ] Week03 (1) | 2024.02.01 |